
Hadoop 协议处理器
相关注释文件为:
org/apache/hadoop/fs/FsUrlStreamHandlerFactory.javaorg/apache/hadoop/fs/FsUrlStreamHandler.javaorg/apache/hadoop/fs/FsUrlConnection.java
1 引入
Hadoop 中通过集成 FileSystem 抽象类,使其能在不同的文件系统中可移植,要从 Hadoop 文件系统中读取文件,最简单的方法是使用 java.net.URL 打开数据流,从中读数据。
无论是 JAVA 原生的 File 类还是 Hadoop 的 FileSystem 类,他们在将文件对象转换成对应 URI(Uniform Resource Identifier, 统一资源标识符) 时的方法都继承了 java.io.Serializable。所标识的资源可以是文件,也可以是电子邮件地址等。如绝对 URI 由 URI 模式和模式特有部分组成,它们之间由冒号隔开,常用的模式有: file, http, hftp, mailto, telnet, hdfs, har, s3 等标准与非标准自定义模式。
并且很多模式如 http、ftp 和 hdfs 都定义了标准的层次式的模式特有部分,为:
1 | //授权机构/路径?查询( [//<authority>]<path>[?query] ) |
目前大部分 URI 使用 Internet 主机作授权机构:
1 | 用户信息@主机:端口 ( [userInfor@]<host>[:port] ) |
而为了让 JAVA 程序能够识别 Hadoop 的 hdfs URL 在 Hadoop 2 及后续版本中做了一些修改,其采用了两种方法:
- Hadoop 中不常用:
FsUrlStreamHandlerFactory实例调用java.net.URL对象的setURLStreamHandlerFactory()方法。但是由于每个 JVM 都只能调用一次这个方法,因此如果程序的其他组件已经声明了一个URLStreamHandlerFactory实例,其将无法使用这种方法从 Hadoop 中读取数据。 - Hadoop 使用: 用
FileSystemAPI 来打开文件的输入流,Hadoop 文件系统中通过 Hadoop Path 对象来代表文件,将路径视为一个 Hadoop 文件系统的 URI,如file://localhost/document/test/1.txt。
分别对这两种方法做检验确定 URL/URI 是如何被 Hadoop 处理的:
1.1 从 Hadoop URL 读取数据
1 | public class URLCat { |
开启 hadoop 服务:
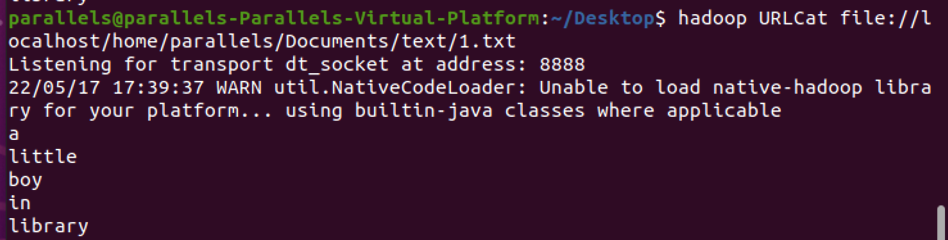
1 | hadoop URLCat file://localhost/home/parallels/Documents/text/1.txt |
此时 URL 传入进来的 args[0] 为文件的地址,通过 openStream 建立输入流:

in 表示有着相应 checksum 的 localBoundedInputStream,因为查找的是本地 file,因此 fs = "LocalFS",conf 为 hadoop 的配置文件。

in 初始 readbuffer 为空,copyBytes 从对应 URL 读取连续 4096 非空 Bytes。

通过 copyBytes 中连续调用的 read,读取 file 的 ASCII 码:

由 RawLocalFileSystem 统计文本中共有 24 Bytes,返回通知 in 能够持续读取 value=24 的字节。

经 read 读好的 24 个字节存入 Byte 数组中,赋值给 InputStream 内的 buf 。

而后由 OutStream 输出从 url 读取的 InputStream 内的 buf 值:

此时,控制台会返回读取的文本数据是什么:
此处说明 Hadoop 通过 IOUtils 类,在 finally 子句中 closeStream 关闭对 InputStream 的读取。
InputStream 和 OutPutStream 通过 read 方法在 System.out 中复制数据。
而 copyBytes 的两个参数,第一个设置了用于复制的缓冲区 buf 大小为 4096,第二个设置了是否自行关闭数据流,默认参数 false 表示选择自行关闭输入流,因此 System.out 不用关闭其输入流。
1.2 通过 FileSystem
1 | public class FileSystemCat { |
开启 Hadoop 服务:
1 | hadoop FileSystemCat file://localhost/home/parallels/Documents/text/1.txt |
首先由 FileSystem.get 静态方法获取服务器的配置,通过设置配置文件的读取类文件来实现(如 etc/hadoop/core-site.xml )。在我们的调试代码中,通过给定的 URI 和权限 conf 文件确定要使用的文件系统:

接着 InputStream 类对象 in 读取文件系统中给定 FileSystem path 的 URI 文件,后续的 copyBytes 与 URLCat 方法相同: 通过 InputStream 读取,经 System.out 复制给 OutPutStream 输出。

补充说明:
- 无论是 URL 还是 FileSystem,他们在读取 URL/URI 时都会由 InputStream 确定读取的 fs 是 Local 类型 (LocalRawFileSystem) 还是 Distributed 类型 (HDFS)。
- FileSystem 读取的 URI 为绝对路径,URL 读取的 URL 为相对路径。
2 协议处理
在引入部分实操了 Hadoop URL 类,其通过 FsUrlStreamHandlerFactory() 安装协议处理系统,再由 setURLStreamHandlerFactory() 确定 URL 获取文件资源输入流的系统位置在何处。
协议处理所做的是什么呢?举个例子: 用户如果在支持 hdfs 模式的浏览器地址栏上输入 URL “hdfs://xdFileSystem:port/path/xdu.jpg” 时,浏览器能正确出现流媒体文件 “xdu.jpg” 。在这个过程中 Java 所做的两部分内容为:
- 协议处理 - 设计 Client 端与 Server 端间的交互,如 HDFS 中,Client 必须与 NameNode 通信确定 DataNode 位置后,与 DataNode 通信获取内容的正确路径。
- 内容处理 - 将协议处理获得的内容展示出来,如显示 “xdu.jpg”。
Java 已经将协议处理分成 java.net 包中的四个部分来一起实现协议处理器,这 4 个类分别为: URL (具体类)、URLStreamHandler (抽象类)、URLConnection (抽象类) 和 URLStreamHandlerFactory (接口)。
Hadoop 文件系统的协议处理则继承了 Java 的后三个类,分别为 FsUrlStreamHandler、FsUrlConnection 和 FsUrlStreamHandlerFactory。
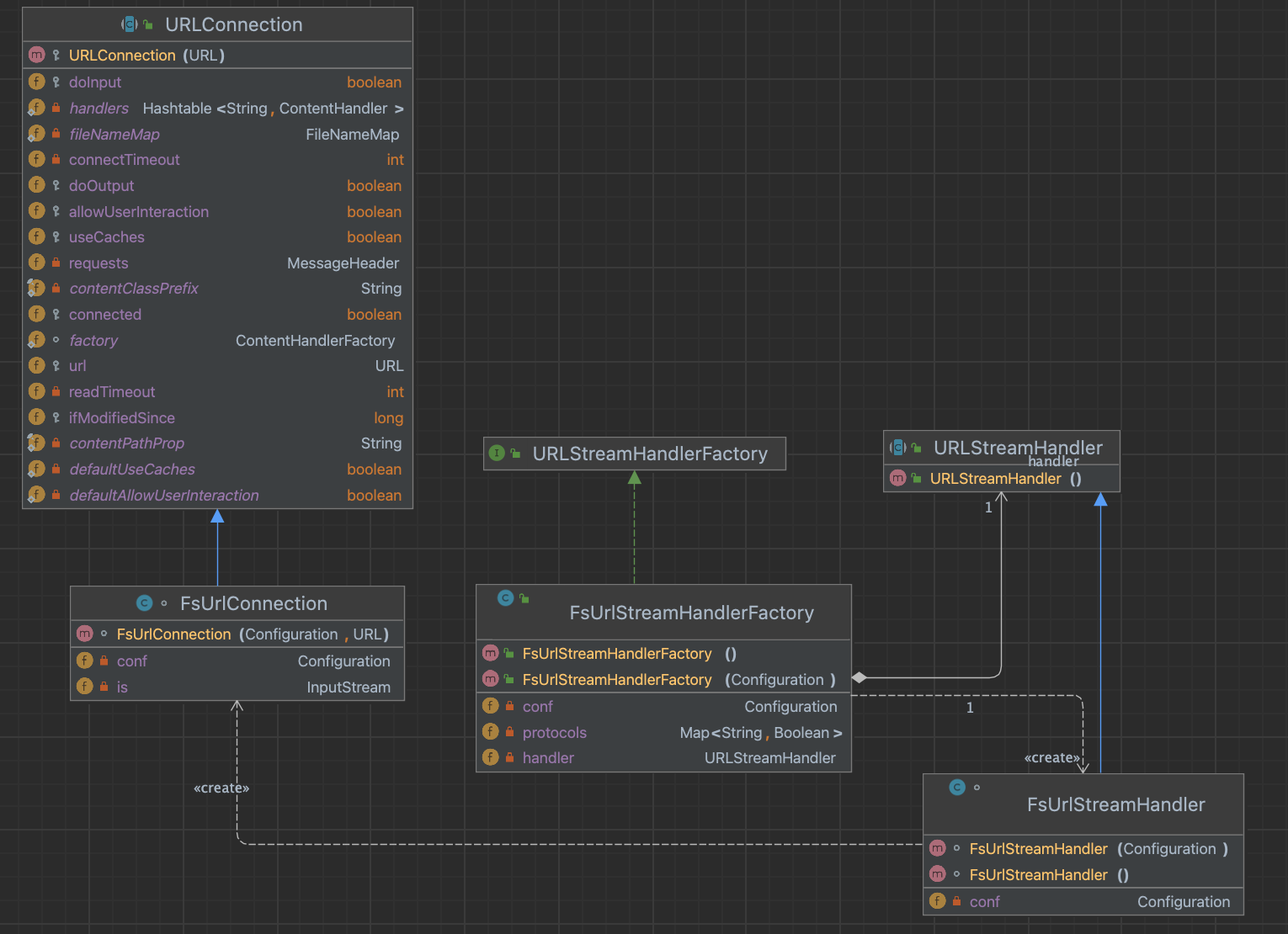
###2.1 安装协议处理系统
结合类图和第一节引用中调试的代码可以知道 Hadoop URL 中调用 URL.openStream() 获得相应 InputStream 对象时发生了什么:由于在引用部分使用的 URL 模式为 file, 在 URL 的构造函数中,file 模式通过 createURLStreamHandler() 由 setURLStreamHandler() 注册,实现 URLStreamHandlerFactory 接口的具体对象,此时的 Factory 任务为接受协议 file,为 file 协议找到合适的 URLStreamHandler,创建 file 流处理器对象并保存在 URL 对象的内部成员变量中。
由于每个应用程序最多只有一个 URLStramHandlerFactory,对于 Hadoop 这样的分布式系统若其试图实现另一个 Factory 时会跑出 Error。因此,Hadoop 用户可以通过 FsUrlStreamHandlerFactory 传入相应的 Hadoop Path(URI) 作文件的多次访问。
2.2 URL 字符串解析
获得文件流处理器后,Hadoop 中通过解析 URL 字符串创建知道使用 对应 protocol(协议) 来与 server 通信的 FsUrlConnection 子类。如在引用 1.2 的例子中,FsUrlConnection.getInputStream() 被调用来打开 “1.txt” 对应 URL 的一个输入流。
到这里,构造 URL 并打开对应 URL 资源的过程结束。
3 具体分析
3.1 具体过程
由引用 1.1 代码来做 URL 模式分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}由 FsUrlStreamHandlerFactory 根据输入的 URL 模式返回相应的 URLStreamHandler,如果没有指定 conf,则默认从
core-default.xml中获取 Hadoop 已默认存储好的 FileSystem Class。由引用 1.2 代码做 URLStreamHandler 子类 FsUrlStreamHandler 读取文件的分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class FileSystemCat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}FsUrlStreamHandler 采用 FileSystem.get() 实现通过指定 conf 访问对应 URI ,能够根据传入的 conf 设置来支持用户实现好的 Hadoop 抽象文件系统,并能匹配在系统中已经进行了配置的多个具体文件系统的 URL 模式。
这样不需要为每一个具体文件系统对应的 URLStreamHandler 子类,而 FsUrlStreamHandlerFactory 和 FsUrlStreamHandler 也能够根据 conf 和 URI.create() 的模式做出使用什么 FileSystem 的判断。
3.2 具体类分析
FsUrlStreamHandlerFactory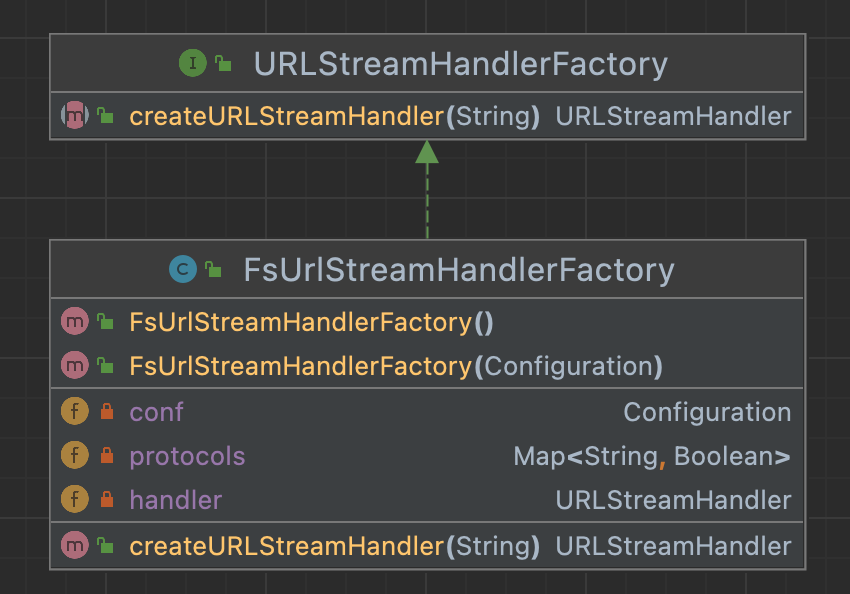
为 URLStreamHanlerFactory 的子类。
两个构造函数,第一个提供默认的 Configuration 对象,因为 Configuration 类由延迟加载,所以通过在构造函数中调用 this.conf.getClass(),能确保 Configuration 对象加载了配置项。第二个指定 conf,引用1.1中使用的是默认 Configuration 对象,返回为:
Configuration: core-default.xml, core-site.xml, mapred-default.xml, mapped-default.xml, yarn-default.xml, yarn-site.xml。调用 createURLStreamHandler() 以 protocol 形式指定 URL 模式,如引用 1.1 中以 file 作为 String 传递给这个方法。

该方法中首先判断目前的 conf 是否支持传入的 URL 模式,由 getFileSystemClass(protocol, conf) 完成。如果支持,返回万能 FsUrlStreamHandler 对象;否则返回 null,交由 JVM 处继续处理。
FsUrlStreamHandler
- openConnection() 返回新的 FsUrlConnection 对象用于建立 URL 的输入输出流。
- 该类的两个构造函数的意义与 FsUrlStreamHandlerFactory 相同。
FsUrlConnection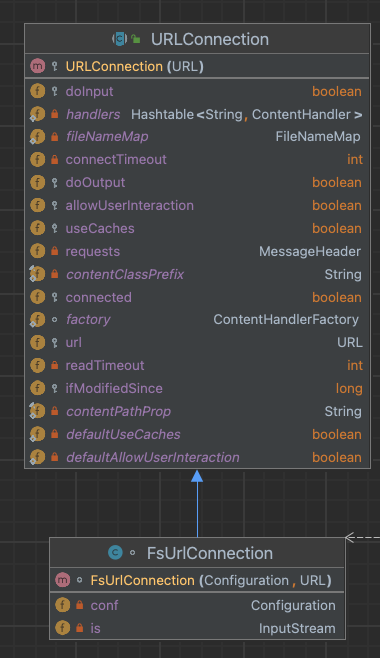
构造函数需要确定 Configuration 对象和有可用的 URL 模式。
getInputStream() 方法继承了 URL.openStream(),返回对应 URL 的输入流。
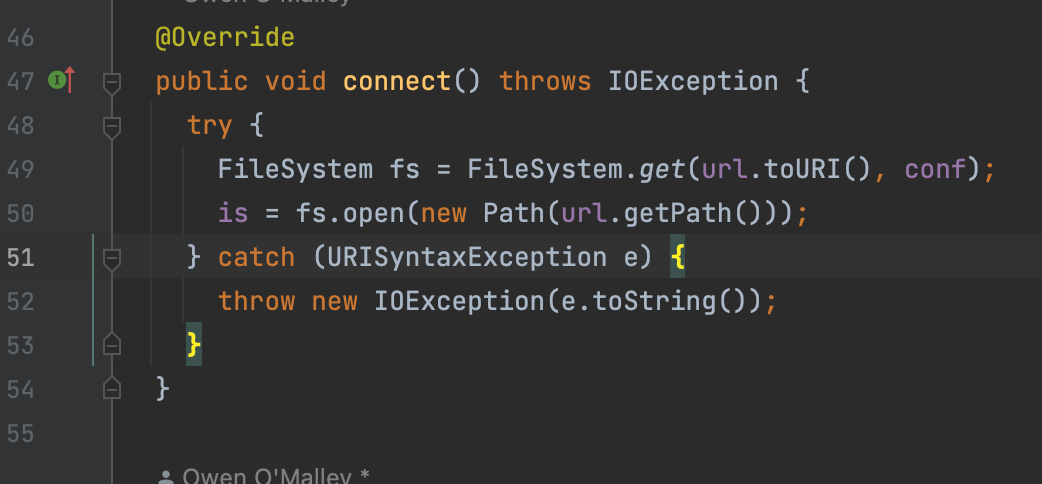
若获取的 InputStream is 为空,调用 connect() 使用 FileSystem.get() 获取 URL 对应的具体文件系统,并调用 open 的方法获取对应的输入流对象:
附录
知识补充
URI 和 URL
URI - Uniform Resource Identifier
File, http, ftp, mailto, telnet
URL (Uniform Resource Location) 为 URI 的一种类型
表示 Internet 某个位置的资源,可以指定用于访问服务器的协议 (FTP、HTTP)、服务器的名称和文件在此服务器上的位置
1
协议: //用户信息@主机号: 端口/路径?查询#片段
输入 / 输出流
stream
- 表示任何有能力产出数据的数据源,或有能力接受数据的接受端
- stream 的源和端可以是文件,也可以是内存块、网络甚至是声卡等设备。
- 输入流(InputStream): 可以读取 (read) 字节序列的对象。输出流(OutputStream): 可以写入 (write) 字节序列的对象

