
LSM-Tree 概述
摘要
- 相比于传统的 in-place updates,LSM-Tree 第一次写入都会缓存到内存中,通过后台的 flush 顺序追加到磁盘里,即 out-of-place update
LSM-Tree Basic
回顾 LSM-tree 历史,讨论 LSM-Tree 结构,对 LSM-Tree 的写入/读取/空间利用作成本分析。
History
index-structure 分为就地更新和非就地更新两种。

图 a 直接覆盖旧记录,这种设计会牺牲写入性能,因为更新会导致随机 I/O,并且索引页通过更新和删除操作会产生分段,降低了空间利用率
为什么会导致随机 I/O?
图 b 将更新变化存储到新位置,不覆盖旧条目。这样设计利用顺序 I/O 来处理写操作,可以提高写性能;不覆盖旧数据,简化了恢复过程。
但是其存在的问题是:记录可能存储在任何位置,会牺牲读取性能。因此 out-of-place 结构通常需要单独的数据重组来提高存储/查询效率。
顺序进行非就地更新的想法在80年代已用于 log-structure 存储结构的数据库中:
- 如 Postgres 将所有写入追加到顺序日志中,实现快速恢复和基于 snapshot 的查询,使用 vacuum cleaner 从日志中删除过时记录(垃圾手机)
LSM-Tree 前,以 log-structure 存储的方法存在几个问题:
- 数据存储仅仅存储到追加日志会导致查询性能下降,因为相关记录分散在整个日志中
- 过时记录没有及时删除会导致空间利用率低,即使设计了各种数据重组过程,但无统一的成本模型来分析 Read/Write 成本和空间利用率之间的关系,因此很难找到可优化的点
- 数据重组容易成为性能瓶颈
96 年提出的 LSM-Tree 将 merge 操作继承到结构本身解决上述问题,提供较高的写入吞吐,基于范围的高效查找和友好的空间利用率。
原始 LSM-Tree 包含一系列组件 $C_0, …, C_k$,如图 2。每个组件都被构造为 B+ Tree。$C_0$ 驻留在内存中处理传入的写操作,所有其余组件 $C_1, …, C_k$ 驻留在 Disk 里。
当 $C_i$ 满时,触动滚动合并过程,将一系列范围为 $C_i$ 的叶子页面合并为 $C_{i+1}$
如今基于 LSM 的存储系统没有使用滚动合并,而是确保所有相邻组件之间的大小比率为 $T_i = \frac{C_{i+1}}{C_i}$ 相同时,写性能得到优化。

Jagadish 提出了 stepped-merge 分层合并策略 ,实现更好的写入性能。它将组件 $C_i$ 组织到各个级别 $L_i$ 中。当 $L_i$ 充满 $T$ 组件时,这些 $T$ 组件会合并在一起成为级别 $L_{i+1}$ 的新组件。
Now-using LSM-Tree
Basic Structure
当前 LSM-Tree 为 out-of-place updates,通过顺序 I/O 来提升写性能,所有写入都会被追加到内存中的组件。任何操作(更新 / 插入 / 删除)也都会以一个新的纪录添加到内存当中。
这个应该指操作后的值?还是 DELETE/UPDATES/INSERT 操作添加进来?
当今 LSM-Tree 通常用 skip-list / B+-Tree 组织内存组件,使用 B+-Tree / SSTables 组织磁盘组件,SSTable 包含一个数据块列表和一个索引块,数据块存储按 Key 值排序的 Key-Value 对,索引块存储所有数据块的 Key 范围。
SSTables 由内存中的平衡树通过中序遍历顺序写入磁盘中得到。

在 LSM-Tree 上的查询必须搜索多个组件,即确定每个 key 的最新版本:
点查询寻找特定 key 的 value,会简单地从最新到最旧一个一个地搜索所有组件,在找到第一个匹配项后停止查询
BloomFilter 会优化查找不存在的组件
范围查询会同时搜索所有组件,将搜索结果输入优先级队列来获取最新数据。
由于磁盘组件会随时间推移而逐渐变多,当组件变得更多时,为避免 LSM-Tree 查询性能内下降,磁盘组件会逐渐合并减少组件总数。
两种合并策略:

图 a 每个 Level 只维护一个组件,每个级别 L 只维护一个组件,而级别 L 会比级别 L-1 大 T 倍。因此级别 L 会与级别 L-1 的组件多次合并,直到级别 L 被填满,合并为级别 L+1。
如图 a 中 L0 的组件会与 L1 合并使得 L1 更大。
图 b 中每个 Level 可能维护 T 个组件,当 Level 已满时,这些组件会合并在一起成为 L+1 的新组件。若 L 已经是最大级别 $L_{max}$ 时,组件会保持在 $L_{max}$。
如在图 b 中,L0的两个组件合并形成一个 L1 的新组件。
由于 LSM-Tree 中要搜索的组件较少,因此分层合并策略针对查询性能进行了优化。而其降低了合并概率因而对写入也进行了更多的优化。
常见 LSM-Tree 优化
BloomFilter
原理: 通过计算的 Hash 值将结果映射到位向量的多个位置,检查这些位置是否都为 1,仅当都为 1 时,能确定查询的 key 可能存在。
设计: BloomFilter 通常设计在磁盘组件的顶部,当搜索磁盘组件时,点查找查询首先会检查其 BloomFilteer,得到确定答案后再向下继续搜索其 B+-Tree。
或者也会为每个叶子页构建一个 BloomFilter,此时点查找会先搜索 B+-Tree 非叶子页面找到叶子页面后,在该叶子页面中假定非叶子页面足够小以进行缓存,然后检查关联的 BloomFilter,再获取叶子页面以减少磁盘 I/O。
缓存的是什么呢?举个例子: B+-Tree 的非 L0 索引节点
分区
指将 LSM-Tree 的磁盘组件范围划分为多个小分区,即 SSTable
划分为 SSTable 的好处有很多:
分区将大型组件合并分解为成了多个较小的合并操作,限制了每个合并操作的处理时间以及创建新组件所需的临时磁盘空间
SSTable 仅合并key 值范围重叠的组件
对于分布不均匀数据的更新,可以大大降低涉及冷更新范围组件的合并频率。
解释一下: 如 key 的范围为 1~100 的数据,其中经常变化的为 50~100 的范围,如果把 1~100 数据放在一个 SSTable 中,前面的 1~50 就不得不跟着合并等操作。
拆分之后,可以只移动和合并 50~100 范围的 key 所在的 SSTable。
对于顺序创建的 key 值,如果不存在具有重叠 key 范围的组件,基本上不执行合并
将分区应用于 LSM-Tree 早期建议是分区指数文件 ( PE 文件 ), PE 文件包含多个分区,每个分区逻辑上都能够视为独立的 LSM-Tree,如果分区太大,会将其进一步分为两个分区
leveling and tiering 都可以进行调整以支持分区,目前只有基于 leveling policy 已被工业级的 LSM 存储系统 (LevelDB & RocksDB) 完全实现。

LevelDB 的分区合并策略中,每个级别的磁盘组件范围划分为多个固定大小的 SSTable,如上图所示,每个 SSTable 在图中均标有 key 值范围:
- L0 未分区,因为 L0 是直接从内存中 flush 下来的。这样设计也能够处理突发写入场景,因为 L1 能接受 L0 的多个未分区组件。
- 要将 L 级的 SSTable 合并到 L+1 级,需要选择 L+1 级的所有重叠 SSTable,后选择 L+1 的 SSTables 与 L 的 SSTables 合并生成仍处于 L+1 级的新 SSTables
- 举个例子: L1 标记为 0-30 的 SSTable 与级别 2 标记为 0-15,16-32 的 SSTable 合并时,此合并会生成标记为 0-10,11-19 和级别 2 中的 20-32。旧的 SSTables 将被垃圾收集,可以使用不同的策略选择每个级别下要合并的 SSTables。
为什么生成的范围在 0-10,11-19 和 20-32 呢
分区优化也应用于分层合并策略。有垂直分组和水平分组:
垂直分组
垂直分组将具有重叠 Key 值范围的 SSTables 分组在一起,以便分组间的 Key 值不相交。

此方案中将具有重叠 key 的 SSTables 分组在一起,以便这些组具有不相交的 Key 范围。合并操作期间,组中所有 SSTables 合并在一起,根据下一级重叠组的 key 范围生成最终的 SSTable,然后把这些 SSTable 添加到重叠组中。
举个例子: 图中将 L1 中 0-30 和 0-31 的SSTable 合并在一起生成标记为 0-12 与 17-31 的 SSTable,然后把它们添加到 L2 的重叠组中。
水平分组
水平分组中,每个逻辑磁盘组件(范围划分为一组 SSTable)用作一个组,这允许以 SSTables 为单位逐步形成更大的 SSTable。
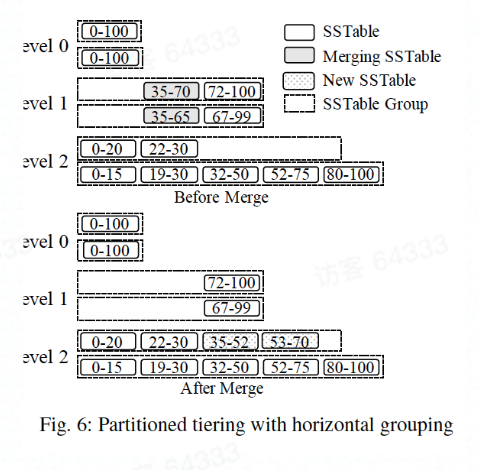
合并操作为一个级别的所有组中选择具有重叠 Key 的 SSTables,将生成的 SSTables 添加到下一级的活动组中。
举个例子: L1 中 35-70 和 35-65 的 SSTables 合并在一起,将结果标记为 35-52 和 53-70 的 SSTable 添加到 L2 中。
并发控制与恢复
根据事务隔离要求,当今 LSM-tree 使用多版本方案。多版本方案可以和 LSM-Tree 自燃地对 Key 作垃圾收集。但是,并发的刷新和合并操作对于 LSM-Tree 是唯一的,这些操作会修改 LSM-Tree 的 Metadata (如活动组件的列表),因此需要同步对组件 Metadata 的访问。
为了防止删除使用中的组件,每个组件都可以维护一个引用计数器,在访问 LSM-Tree 组件前,查询获得组件的 snapshot 并增加该组件的计数器。
由于所有写操作都会先添加到内存中,通过执行预写日志记录(WAL Write Ahead Log) 取保持久性。为了简化恢复过程,现有系统使用 no-steal 缓冲区管理策略。
NO-STEAL: 没有 commit 的 transaction 修改的 page 不可以写入 Disk 中
NO-STEAL 保证当所有的写事务停止时才刷新。通过重做事务日志以重做所有成功的事务,由于采用了 “no-steal” 策略,因此不需要撤销操作。
LSM-Tree Improvement

LSM-Tree 存在问题
写放大
leveling 合并策略仍然会有较高的写入放大率。高写入放大率不仅限制了 LSM-Tree 的写入性能,而频繁的磁盘写入也缩短了 SSD 的使用寿命
合并
合并后的缓冲区中的高速 Cache 是否命中以及超大合并期间的写入停顿如何改善
硬件
实施 LSM-tree 更好利用硬件平台,包括 大内存/多核/SSD/NVM 和 块存储
Auto-tuning
根据给定工作负载根据场景自动调整到读取最佳、写入最佳和空间最佳。
二级索引
因为 LSM-Tree 仅提供简单的 Key-Value 接口,为支持对非关键属性查询的有效处理,必须维护辅助索引。该领域的一个问题是如何以少量的写性能开销有效地维护一组相关的二级索引。
改进 LSM-Tree
减少写放大
主要优化 Tiering 合并策略,因为 Tiering 拥有比较好的写性能,且不弱于 Leveling 的读性能。
分层
一种优化写放大的方法是应用分层,因为其写放大比 leveling 低得多,但这会导致更差的查询性能和空间利用率。可以将此类中的所有改进看为是垂直/水平分组的分区设计的变体。目前主要有做的修改有:
WriteBuffer (WB) 树
可以看作垂直分则设计的变体
- 由 Hash 分片来限制每一个 SST 文件都有相同大小的数据,从而均衡用户态 workload
- 将每一层 SST 文件 (Tiering 会将每一层 key 范围相近的 SST 作为一个文件组,用作下一次的合并) 组织成一个 B+Tree 的形态。
LWC-Tree
提供了一种 workload 的均衡策略。

