
LevelDB 源码分析 (一) | 前沿和基本组件
What is LevelDB
LevelDB 是 KV 型数据库,为 BSD 协议,为 Leveling+分区 实现的 LSM 代表,适合写多读少。
特性
- Key Value 支持任意 Byte 类型数组,不单单支持字符串
- 为持久化存储的 KV 系统,大部分数据存在磁盘上
- 按照 key 值顺序存储数据,按照用户定义的比较函数进行排序
- 操作接口简单,包括写/读记录以及删除记录,也支持针对多条操作的原子批量操作
- 支持 snapshot,读写操作互不影响
- 支持 snappy 压缩,I/O 效率高
源码编译
直接 clone
1
git clone https://github.com/google/leveldb.git
initialize submodule issues#1004
1
2
3
4
5# 一步到位
git clone --recurse-submodules https://github.com/google/leveldb.git
# without re-cloning
git submodule update --init --recursive编译
1
2
3
4
5
6
7cd leveldb
mkdir -p build && cd build
# Release
cmake -DCMAKE_BUILD_TYPE=Release .. && cmake --build .
# Debug 方便跟踪还是 Debug 伐
cmake -DCMAKE_BUILD_TYPE=Debug .. && cmake --build .为方便将 levelDB 加入到系统库
1
2
3
4
5# Linux
cp -r ./include/leveldb /usr/include/
cp build/libleveldb.a /usr/local/lib/
# MacOS waiting
基本组件

字节序 Endian

一般都是小端序,将低序字节存在起始位置的为小端序,反之为大端序。以 short 2B 数据作测试:
1 | /* RETURN "Little Endian" */ |
slice
slice 为 levelDB 自定义的数据结构,在 include\leveldb\slice.h 中,不用 string 的原因是 CPP 中 string 为拷贝变量,不支持 remove_prefix, starts_with 的操作,不灵活。
1 | // Snippets of `slice.h` |
status
status.h用于记录 levelDB 中状态信息,保存错误码和对应的字符串错误信息(不支持自定义)。基本组成为:

Status 具有特色的私有变量为:
1 | private: |
具体实现为:
1 | /*status.cc*/ |
编码
levelDB 中分为定长和变长编码,变长编码目的是为了减少空间占用,基本思想为:每一个 Byte 最高位 bit 用 0/1 表示该整数是否结束,用剩余 7-bit 表示实际的数值,在 protobuf 中被广泛使用。
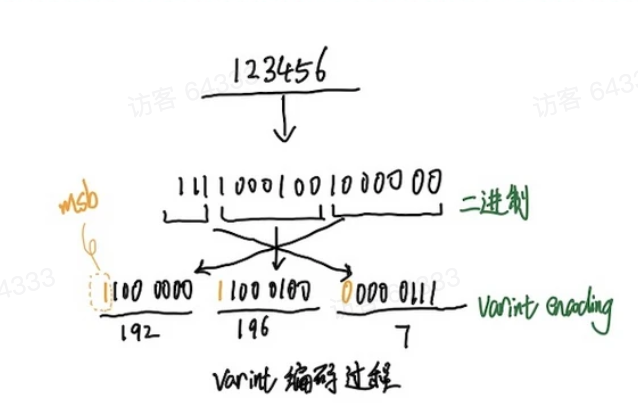
if-else 根据数值 v 来判断是否需要继续变长。B 作为最高位来表示整数是否结束。
1 | /* util\coding.cc */ |
Option
- Option 记录了 levelDB 中的参数信息,用来控制 levelDB 的控制信息
- 通用(如 block 数据大小和读写设置):
options.hGitHub - LSM存储设置:
dbformat.hGitHub
skiplist
常规线段跳表
- 定义
skiplist 用于代替平衡树,可以看作是并联的有序链表。skiplist 通过概率保证平衡,平衡树采用严格的旋转来保证平衡,因此 skiplist 比较容易实现,并且相比平衡树有着较高的运行效率。
Redis 中也是 skiplist,其默认最大的 level 为64

db/skiplist.h
引用
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Sicilienne!
相关推荐


评论
Valine# ValineDisqus