
Reading | 存储上的软硬件协同
存储上的软硬件协同
Introduction
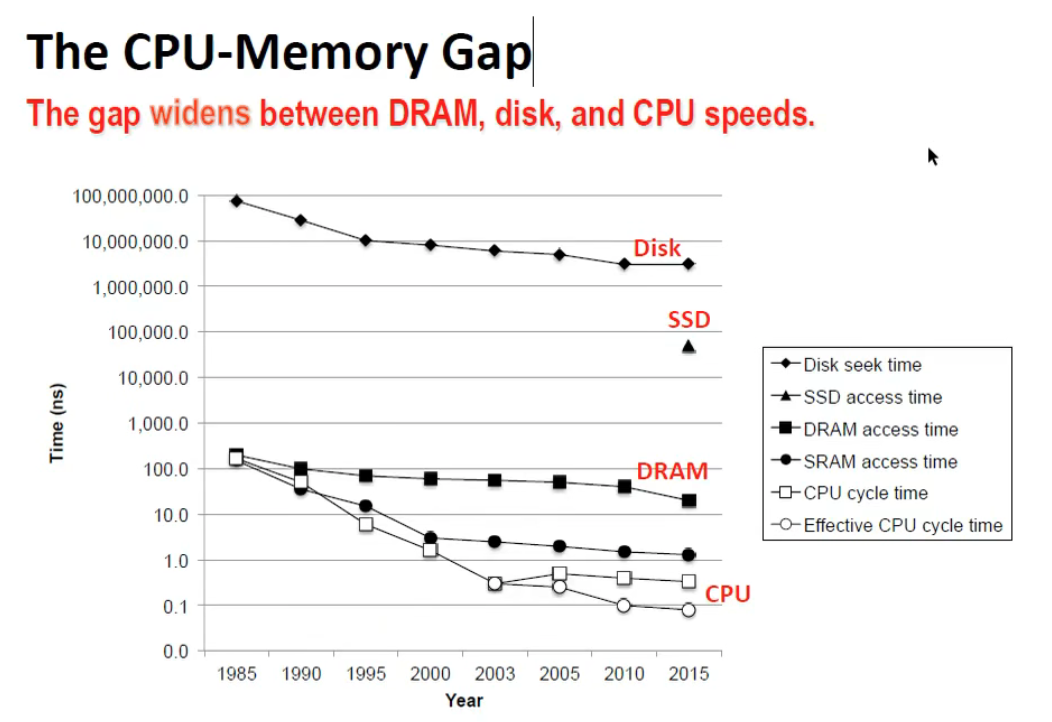
- CPU 和 Memory 的 gap 越来越大,目前朝着多核发展有所缓和,但还是有很大的 gap
- Disk 速度更慢,目前用一些软件方法来解决如操作系统将经常使用的数据存储在主存中,相比访问磁盘提高了访问速度
- 毫无疑问,主存是目前系统的瓶颈:
- RAM 硬件设计 (速度和并行化)
- 内存控制做更优的设计
- CPU caches
- DMA for devices
现代硬件 (07年) - Commodity Hardware Today
Intro
除了 DDR4 还在发展,07 年的硬件和现在没有什么区别

最初的系统分为南北桥,北桥为 CPU 和内存控制器的接口,南桥主要为 I/O 的接口。
这种设计会有很多限制:
- 与 RAM 之间的通信都需要通过北桥
- CPU 间的通信需要通过北桥上的同一总线
- RAM 只有一个接口

改进设计: 将北桥与外部内存控制器作分离的设计,这样可以增大带宽
这样的设计瓶颈为北桥带宽

- NUMA - 非一致性内存架构
- CPU 相互通信也有一定成本
RAM Types
分为 SRAM 和 DRAM,主要在于成本差异,前贵后弱
SRAM

1-bit 的 SRAM 通常由 6 颗晶体管组成成本较高,但是不需要刷新。
- WL - 置线
- 成本较高,但是不需要刷新,可以让数据保持原来的样子
DRAM
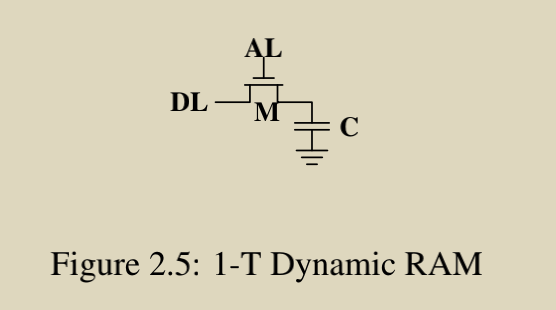
1-bit DRAM由一个电容和一个晶体管组成,成本较低,但是需要刷新
- 刷新: 因为电容会漏电
- For most DRAM chips these days this refresh mush happen every 64ns.
电容的充放电特性:

R: 电阻 C: 电容容量大小 乘积是某时间单位
DRAM Access

- DRAM 以阵列的形式进行排列,每个单元进行 1bit 的存储
- 左边为
行选通信号,下边为列选通信号,读取时低电平有效,选中行选中列确定1-bit - 设计看起来很简单,但是掀起来还是很复杂的,设计很多细节特别是和电容的特性有关
DRAM Access Technical Details
Read Access Protocol

SDRAM (同步DRAM) 读数据时序图
注意:完整的时序还包括行预充电等过程,参见图2.9
- $t_{RCD}:$ Row Addr 和 Col Addr 传入的时间差
- $CL:$ 给出 Col Addr 后还需要等待一段时间 $CL$
Precharge and Activation

- 在读操作前,行选通信号(蓝色部分)已经在做准备,也就是 $t_{RP} \ (Row\ Precharge)$ 这段时间
DDR 参数:

Recharging
重新充电的时间即为上述提到的 64ns
Memory Type
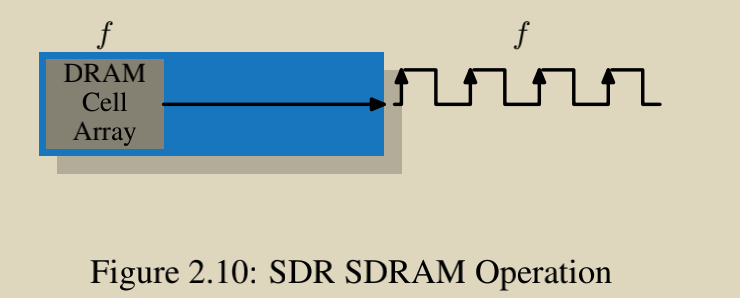
从 SDR (Single Date Rate) 到 DDR (Double Data Rate) SDRAMs 的基础 SDRAM
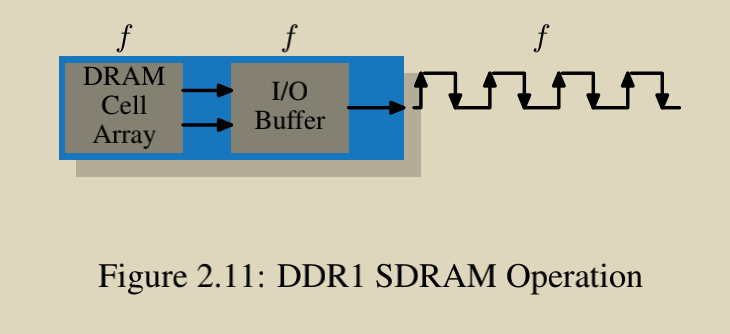
- 频率无变化,通路加倍

- 频率加倍,通路加倍

- 频率继续加倍,通道也继续加倍
目前已经发展到了 DDR4。
CPU Caches

成本越高 速度越快
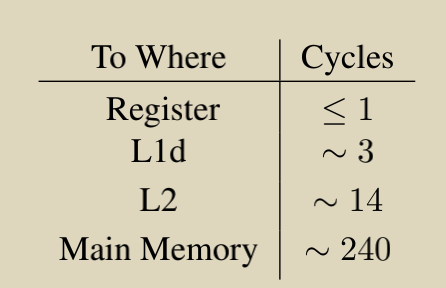
04年的数据数量级上的差异:

- 首先,CPU Cache 对用户来说是透明的,也可以说是对编译器
- 程序和数据的时间局部性和空间局部性:比如同一段代码反复被执行 (循环) 或者访问一块连续的内存空间 (数组)就是空间局部性的例子,频繁访问同一个局部变量就是时间局部性的例子
- 但是程序员依旧需要帮助处理器去充分利用 Cache
CPU Caches in the Big Picture

冯诺依曼结构的经验表示尽量采取指令缓存和数据缓存分离的设计,因此之后的 Cache 是将指令和数据分离的
注意: 实际上 CPU 流水线设计中的结构冒险的一种场景即指令和数据需要同时访问内存,Cache 中指令和数据分离的设计恰好解决了结构冒险这个问题。

- L1 指令和数据缓存分开,L2 和 L3 再放在一起
- 具体实现由 CPU 设计人员确定,对程序员来说是不可见的

多核多处理器多线程示意图

Cache Operation at High Level
CPU 缓存以“行”形式来存放的,叫做 Cache Line,利用了空间局部性。早期 Cache line 是 32B,现在是 64B。
也有 128B,如高通 Qualcomm Centriq Falkor,主要用于数据中心作服务器

CPU 缓存设计根据不同场景作权衡
CPU 内部 Cache 的组织方式:

- Offset 数据偏移量
- Cache Set 缓存集
- Tag 缓存集里面哪个数据是需要的缓存行 (如
dirty flag)
其他的操作:
缓存一致性
多处理器 / 多核上可能存在缓存一致性问题,通过一些协议,如最重要的 MESI 来解决
命中率
缓存不命中的可能原因为: 1) 强制性不明中 2) 容量原因不命中 3) 冲突原因不命中。
读取周期 (Pentinum M)
随机写情况下根据不同的数据量引起的 CPU 操作时间上的差异。

CPU Cache Implementation Details
Associativity - 关联度
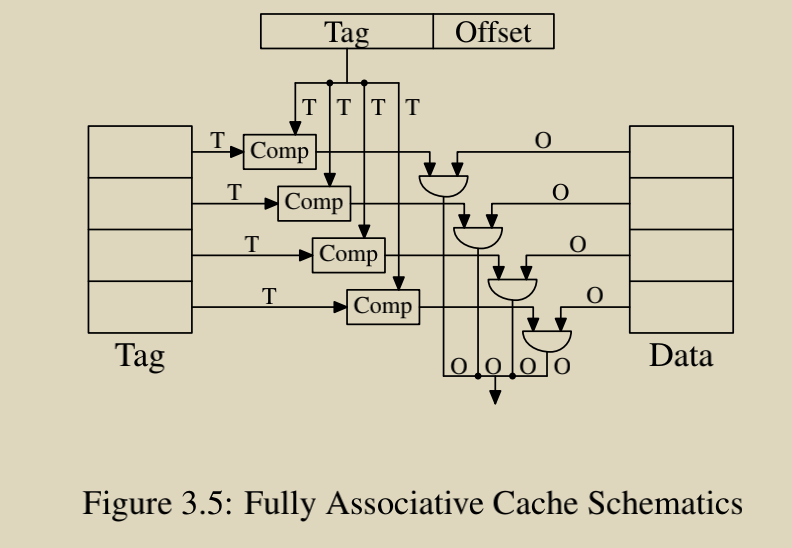
Fully Asscociative Cache Schematics - 全关联缓存
相当于缓存集为 1 (没有了 Cache Set),缓存行可以存放在任意位置,但是硬件实现困难,成本也高。
只适用于“真的非常小”的缓存,如 TLB。
Direct-Mapped Cache Schematics - 直接映射缓存

Set 选择某一路,Tag 进行比较就可以得到缓存行
Set-Asscociative Cache Scematiccs - 组关联缓存

确定在那个 Set 中,在 Set 内进行比较。
大部分情况下都是组关联缓存,L1 常是 8-set(8路) 的。
Cache 的大小和关联性:
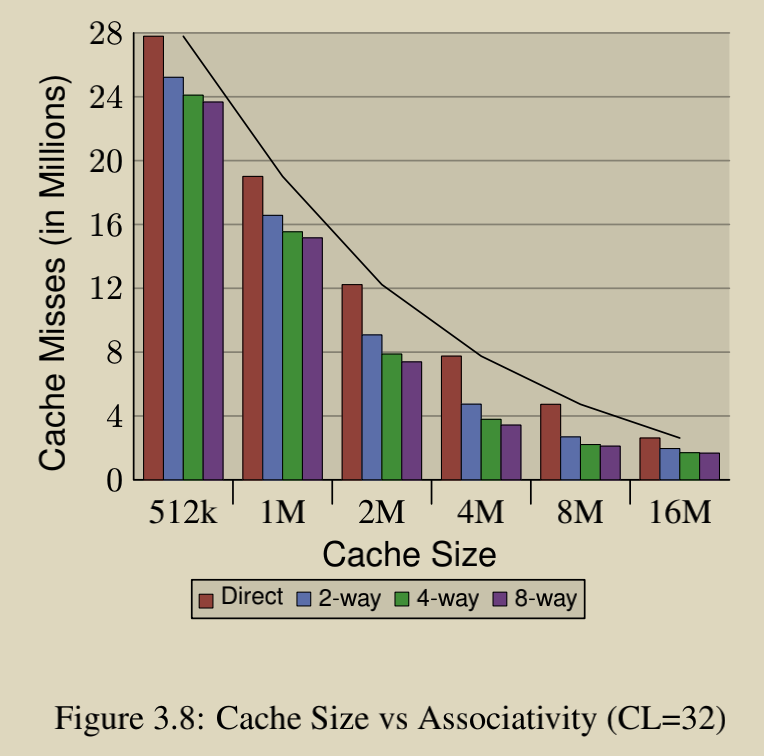
缓存越大,miss 的概率越小。
Measurement of Cache Effects
这一节主要讲第四章的 TLB,会说明 Cache 的衡量指标。
多用
perf
Write-Behavior
写行为一般可分为两种:
- Write-Through 写通
- Write-Back 写回
Write-Through: 缓存行一旦被改写,需要立即同步更新主存
Write-Back: 缓存行一旦被改写,不会立即更新心存,仅作“脏数据”标记。等到改行即将被逐出之前,检查“脏标记”,需要的话再写会主存。
写回策略的显著问题: 多处理器 / 多核的缓存一致性问题 - MESI
Multi-Processor Support
保持 Cache 一致性的协议常用为 MESI

MESI 协议转换图,多在网上找找其他资料熟悉一下

Other Details
缓存替换策略常用的即 LRU,或者也可以随机替换(但很少见)。
Virtual Memory - 虚拟内存
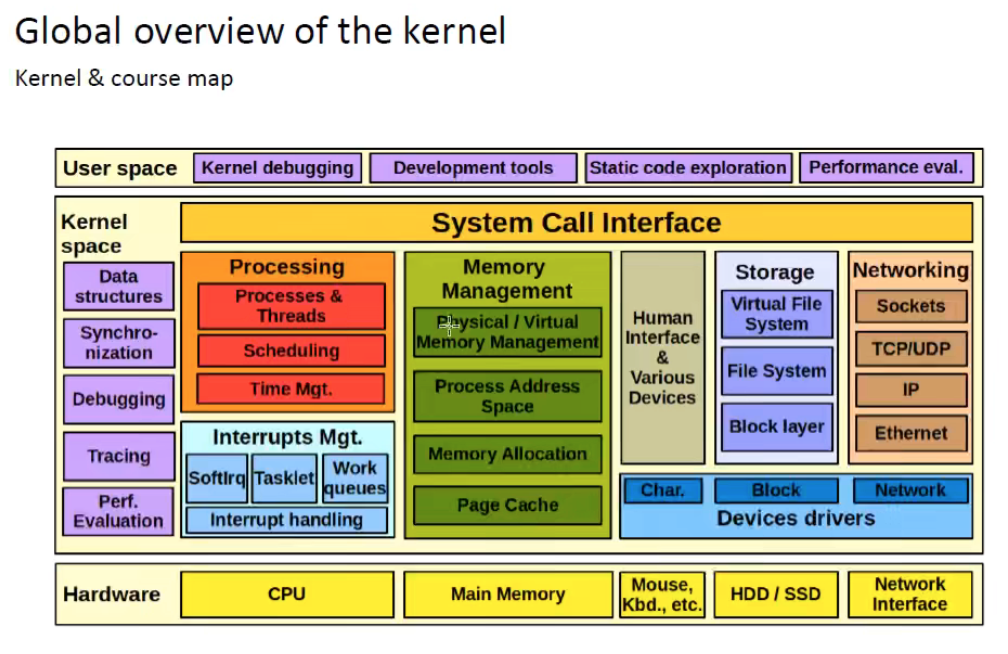
这部分内容和 OS 密切相关,比如进程管理中 fork 一个进程时的 Copy on Write,缺页时的 Page Fault Handler 等。
为什么需要 VM? Problems?

重点: program’s mem space to the RAM mem space.
Virtual Memory is a layer of indirection

可以把 Disk 中的页载入到存储当中去
谈谈如何解决上述 Cache 中的三个问题:
#1 not enough memory

通过 LRU 将 old data 换出到 Disk 中,new data 换入到 RAM 内,mapping 机制使得内存看起来无穷大:

如果内存空间不够,需要经常去读 Disk,Disk 读速度慢于内存的 1000x,所以内存越大速度越快。
#2 holes in the address space
通过 map 将 program 地址分段映射。

#3 keeping programs secure

虚拟内存可以共享段,如右边
save dialog in Mail/Browser都有相同的部分。
虚拟内存由 MMU 实现,虚拟内存管理是系统中最为复杂的部分之一,比如 Slob/Slab/Slub,还有 Overcommit 以及 OOM 这样的机制,在 Linux 环境下有 /proc/meminfo 描述了虚拟内存的复杂性。
Simplest Address Translation
由一级查找即可找到。

用索引查找在那一页,后根据 Offset 确定物理地址
完整的页表是存放在主存中的。
Multi-Level Page Tables
4KB Pages 一般作为默认值,选择 4K 更多是历史原因,或者说是实践经验值,不去细究。
一级页表需要的存储空间太大,因此采用了多级页表。
page tree walking:

X86-64 为 4KB pages 和 512 entries per directory,内存大小为 $ (2^9)^4 * 2^{12}$
出于安全性考虑,shared libraries 为虚拟地址随机化 (mapped at randomized adddress)
Making virtual memory work
虚拟内存访问成本较高:
每个 memory operation 都需要查找 page table
需要访问 (1) the page table (2) the memory address, 需要耗费 2x 的 memory accesses
1.33 memory accesses per instruction. This is going to hurt.
为了让 VM fast,加入特殊的 **Page Table Cache: TLB(Translation Lookaside Buffer)**,根据局部性远离其设计类似于 L1-Cache:

让 TLB 变快的方法有:
Make pages larger
用少量页存储更多的数据
Add a second TLB that is larger, but a bit slower
Have hardware to fill the TLB

PTE 为 Page Table Entries
影响 TLB 性能的一些因素
- 如果页面大,相应的页表项少,那么 TLB 寻址速度也快,但是页面大容易产生很多碎片
- 如果页面小,碎片相对少,但是页表项多,影响 TLB 寻址速度,因此如何选择是一个折中的方案
- 实际上,大 page 也逐渐支持使用
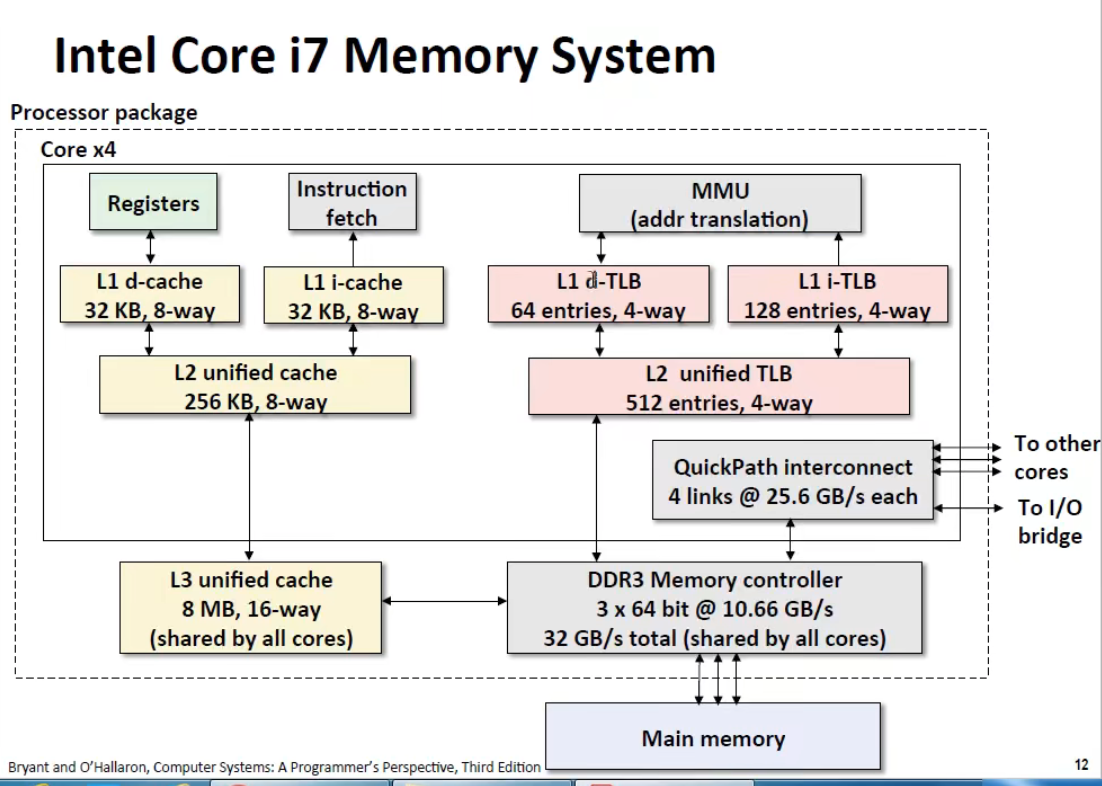
可以看到 Cache 和 TLB 的结构设计上逻辑是差不多的。
Memory Performance Tools
测试内存性能: brendangregg.com - Linux Performance
- 内存金字塔
- 熟悉局部性