
Reading | CDBTune
Reading - CDBTune
Summary
CDBTune 是一个帮助云数据库智能调优的工具,也是最先通过强化学习来找到调优策略方向的 Auto Tuning Tool。
CDBTune 的 contributions 主要为:
- First end-to-end automatic database tuning system.
- Use limited number of samples to learn the best knob settings by try-and-error manner in RL.
- Design a new reward function in RL, accelerates the covergence speed.
- Use DDPG(Deep Deterministic Policy Gradient) method to find the optimal configurations in high-dimensional continuous space.
- Good adaptability and outperforms DBA and Ottertune.
一些 creative points 在 intriguing aspects 处详细说明。
Problems Mentioned
过去 DBMS configuration tuning 存在着如下限制:
Use pipelined learning model but cannot optimize the overall performance in an end-to-end manner.
Rely large-scale high-quality training samples but hard to obtain.
Knobs too much and it’s hard to recommend configurations in such high-dimensional continuous space.
Poor adaptability: In cloud env, former auto-tuning tools hardly cope with changeable hardware configurations and workloads.
Important Related Work/Papers
一般不用看 introduction ,但这个领域刚接触,了解一下其他方法的历史是好的。
Search-based methods
Representative: BestConfig
Method: Search the optimal parameters based on certain principles.
Elaborately, 划分一个参数空间,递归搜索到 best configurations,耗时长,也可能陷入 local optimal.
Limitations:
- Spend much time on searching the optimal configurations.
- When a new request comes, it will restart again, not utilize previous tuning efforts.
Learning-based methods
Representative: OtterTune
Methods: take DBA’s experience as historical datas into machine learning model. Collect, process and analyze knobs then recommend possible settings.
Elaborately, 基于 Pipelined ML,第一步为识别用户 workload 的特征,对参数进行排序;在排序过后,识别配置参数和性能的相关性,找到对性能影响更大的参数;第三步需要匹配 workload,推荐最优参数。
Limitations:
Pipelined learning model’s different stages of model can not work well on each other. Thus couldn’t optimize overall performance.
Session: collect -> recommend : configurations
Rely on large-scale and high-quality training data which is hard to obtain.
E.g. The cloud database affected by various factors, such as memory size, disk capacity, workload, CPU model and database type. And it’s hard to reproduce high-quality samples.

As shown above, OtterTune & Deep OtterTune couldn’t get high performance even though give more samples.
Use Gussain Process(GP) to find the best configurations in high-dimensional space is NP-hard, because knobs’ number will increase.

Knobs in continuous space have unseen dependencies. Due to non-linear correlations, the performance 不会在某个方向上单调改变.
In cloud env, many users often change the hardware configurations, which conventional ML have poor adaptability.
Intriguing Aspects
Working Mechanism - offline/online training
Offline training
- Training Data
1 | INPUT DATA: <q, a, s, r> |
63 internal metrics in CDB, which for 14 state values and 49 cumulative values:
- state values: buffer size, page size, etc. (占了多少size )
- cumulative values: data reads, lock timeout, buffer pool read/write, etc.
All collected metrics and knobs data will be stored in memory pool.
- Training Model
Use deep RL model and adopts try-and-error strategy to train the model.
Model will train offline at initial, later will be tune knobs value for each tuning requests from database users.
- Training Data Generation
2 ways to collect datas.
Cold start
- Use standard testing tools(Sysbench) to generate query workloads $q$.
- For each $q$, execute it on CDB and get the initial quadruple.
- Use try-and-error strategy to train quadruple data and get more training data.
Incremental Training
- System continuously gain feedback from user, with more real user datas, will improve the recommendation accuracy of the model
Online Tuning
When CDB user submit tuning request to system, CDBTune will act in following steps:
- 收集用户过去 150s 内的 query workload $q$,获取其当前的 knobs’ value $a$, 将 $q$ 运行在 CDB 上得到 $s$ 和 $r$。
- Use offline model to do online tuning.
- 最后将提升性能的 knobs configurations 推荐给用户。
- When tuning process terminates, 需要 update deep RL and memory pool.
System Architecture - 整体角度

Workload Generator
Two tasks:
- Generate standard workload testing (Sysbench/TPC-MySQL)
- Replay user’s real workload ( Will collect users’ using data in specific interval )
Metrics Collector
- Collect and process metrics data in a certain time interval, and using average value of them
- External metrics (latency and throughput) taken every 5s and calculate the mean value to calculate reward.
Recommender
- 当 RL model outputs recommended configurations 给 recommerder 时,其会生成对应的 commands,然后将 modifying configurations 的 requests 发送给 controller
- Controller 获得 DBA’s or user’s license 后,将把推荐的 configurations 用于 CDB 上
Memory Pool
- 用于存储 training smaples, samples 表示为 $(s_t, \ r_t, \ a_t, \ s_{t+1})$
1
2
3
4s_t - current data base state
r_t - reward value
a_t - knobs' values
s_{t+1} - after executing the configurations's state
RL in CDBTune
Key way to solve NP-hard: try-and-error strategy
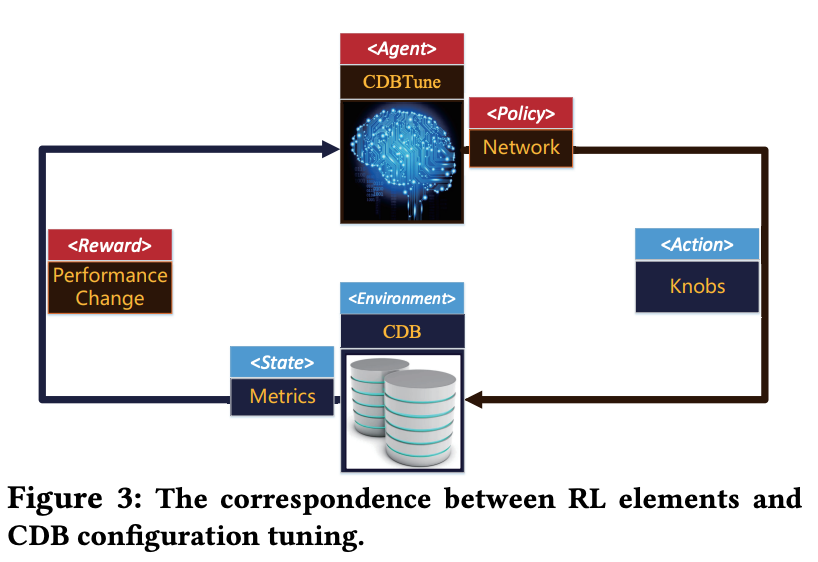
Features:
- Use policy-based DDPG approach which overcomes above shortcomings effectively.
- A newly reward function,
6 roles:
- Agent: CDBTune
- Receive rewards and state from CDB.
- Update the policy.
- Enviornment: CDB
- Tuning target, an instance in CDB.
- State: Metrics
- Reward: Performance change
- Usually latency or throughput.
- Action: Knobs
- Policy: Deep Neural Network
- Mapping from state to action.
- The goal of RL: learn the best policy.
DDPG for Network
DDPG is the combination of DQN and actor-critic alg.
Actor metric -> knob

Policy function (generate actor): $a_t = \mu(s_t|\theta^\mu)$.
Critic function: $Q(s_t, a_t|\theta^Q)$, $\theta^Q$ 是 NN 中表示 $a_t$ 对 $s_t$ 性能影响了多少的 score.
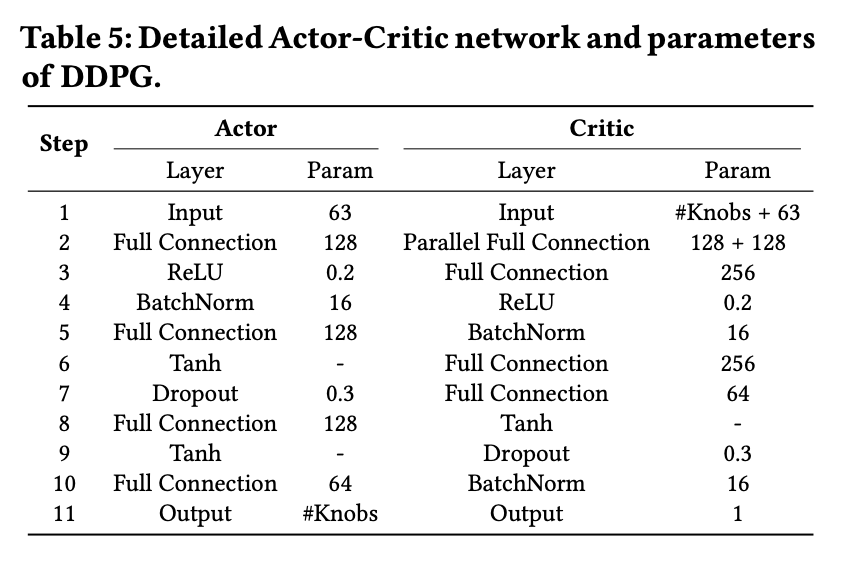
这篇 paper 的网格参数为:
结合 Bellman Equation 和 DQN,$Q(s, a)$ 的期望值可以写为:
$$
Q^\mu(s, a) = \mathbb{E}{r_t, s{t+1} \sim E}[\ r(s_t, a_t) + \gamma Q^\mu(s_{t+1}, \mu(s_{t+1}))\ ]
$$
应用 Q-learning 目标是找到 CDB 中的最优配置(损失函数):
$$
min \ L(\theta^Q) = \mathbb{E}[\ (Q(s, a|\theta^Q)-y)^2\ ]
$$
其中:
$$
y = r(s_t, a_t) + \gamma Q^\mu(s_{t+1}, \mu(s_{t+1})|\theta^Q)
$$
Critic parameters 以梯度下降法更新.
Steps

Remark: Why efficient?
这里解释了为什么小样本用 deep RL 在数据库上可以得到好结果,但在游戏里却不是很理想(如AlaphGo)。
在游戏中难以得到采取 action 后 environment 会如何改变,因为游戏中 environment 的变化是随机的(如在 AlaphGo 中不一定能猜到对手下一步怎么做)。
而在 DBMS tuning 中,由于 knobs 间的 dependecies,用少量样本即可得到 DB 的大部分状态。
Few inputs (63-d) and knobs output (266-d) make the network efficiently converge 而不需要太多 samples。
RL 需要 diverse samples, 而不是 massive redundant samples. 在 DBMS tuning 中,通过改变 DB 的 parameters 采集到 performance data。这些 data 是 diverse 的,而不是像游戏中重复的相同frames。
Reward Function

T - Throughput, L - Latency, r - reward.
如果考虑优化目标只有 T 和 L,令系数和 $C_L+C_T=1$,reward function 表示为:
$$
r = C_T * r_T+C_L*r_L
$$
如果有其他多的优化目标,在 reward function 加即可。
能不能也用 NN 得到最优的 reward 呢?为什么这里没有加这个网络呢?
Improved parts
看完 paper 感觉可以提高效果的地方
- 对于 reward function,$C_T, C_L$ 等 external metrics 是否可以加一个策略来得到最优配置
关于怎么调整权重应该看重用户的需求
Questions
- end-to-end 是指 policy 这块么,为什么说 ottertune 没有利用 end-to-end manner 呢?
- 期望值 $Q^\mu(s, a)$ 怎么求的均值不是很理解,后面loss 为什么用的是过去期望值来减 (但好像 RL 是没有监督数据的,确实 historical data 用期望表示会好)

