
02 - Shell Tools and Scripting
Command: ls args
- Read
man lsand write anlscommand that lists files in the following manner
- Includes all files, including hidden files
- Sizes are listed in human readable format (e.g. 454M instead of 454279954)
- Files are ordered by recency (时效性)
- Output is colorized
1 | $ ls -ahltc |
-h:use unit suffixes: B, KB, MB…
-l:list files in long format
-t:sorted by descending time modified
-c:use time when file status was last changed for sorting or printing.In order to show
.and..:
-a:include dir entries whose names begin with a dot ('.')
Bash functions
- Write bash functions
marcoandpolothat do the following. Whenever you executemarcothe current working directory should be saved in some manner, then when you executepolo, no matter what directory you are in,poloshouldcdyou back to the directory where you executedmarco. For ease of debugging you can write the code in a filemarco.shand (re)load the definitions to your shell by executingsource marco.sh.
The whole processing is:
1 | (base) zoriswangdeMacBook-Pro:xv6Core zoriswang$ vim marco.sh |
1 | // For simplify back to historical command, use `history` or Ctrl+R to check former command. |
But I find a nice shell named fish , by using this, you could find your files more quickly. Such as following shortcutting:

The marco.sh and polo.sh are:
1 | // marco.sh |
1 | // polo.sh |
BASH Redirection
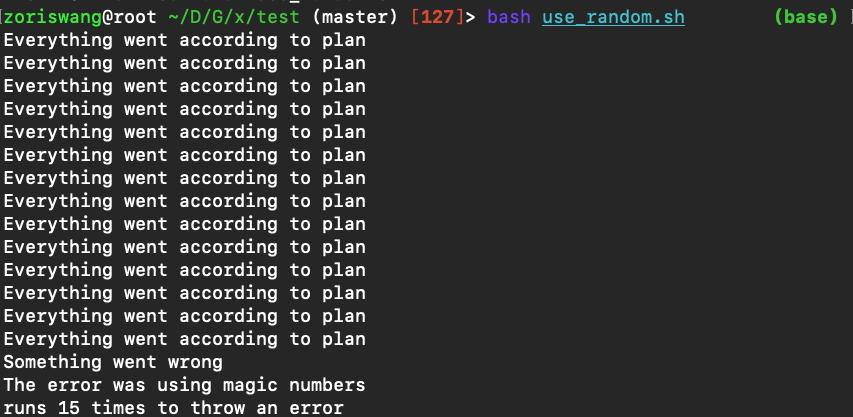
Say you have a command that fails rarely. In order to debug it you need to capture its output but it can be time consuming to get a failure run. Write a bash script that runs the following script until it fails and captures its standard output and error streams to files and prints everything at the end. Bonus points if you can also report how many runs it took for the script to fail.
1
2
3
4
5
6
7
8
9
10
11
n=$(( RANDOM % 100 ))
if [[ n -eq 42 ]]; then
echo "Something went wrong"
>&2 echo "The error was using magic numbers"
exit 1
fi
echo "Everything went according to plan"
Let’s firstly check a demo code: (because I don’t understand grep that line’s function)
1 |
|
> /dev/null 2> /dev/null:将 grep 命令的 STDOUT(1>) 和 STDERR(2>) 都 redirect 到/dev/null设备上,表示舍弃。
/dev/null是特殊的 Linux 虚拟设备,专门用于倾倒不需要的垃圾数据
I find a stupid thing about my code: I always think the scripts only could be run after source and should allocate a specified function to it.
But it could run by add shebang #!/usr/bin/env bash , then use bash xxx.sh to run it is fine…
1 | // use_random.sh |
find & xargs
- Write a command that recursively finds all HTML files in the folder and makes a zip with them. Note that your command should work even if the files have spaces (hint: check
-dflag forxargs).
See some xargs examples by tldr xargs:
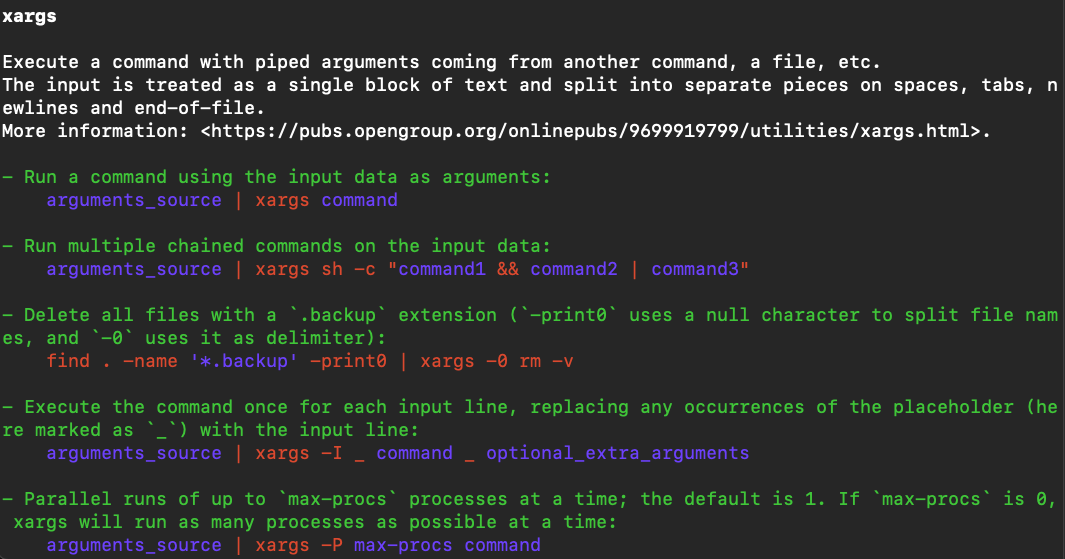
So we could use find to get all html files as xargs arguments, then executes tar to zip thest input files.
What’s more, let’s check tar usage:
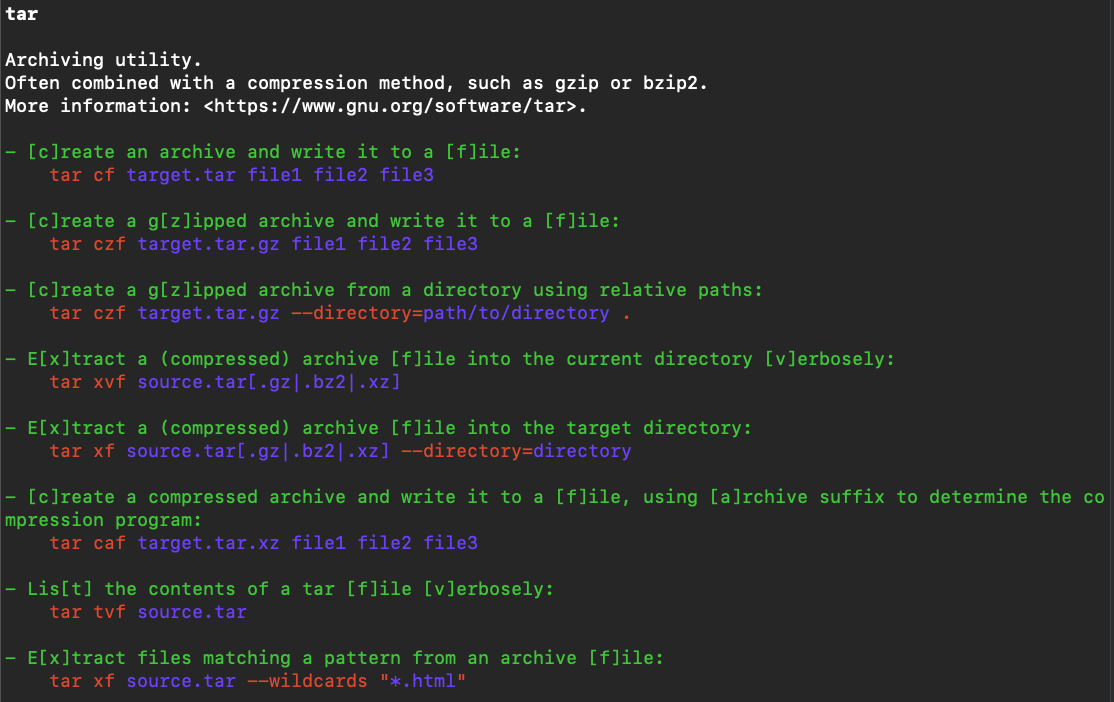
1 | // use this cmd |
List inner files in 4.tar:
1 | $ tar tvf 4.tar |
Then rm them:
1 | $ find 4.tar | xargs rm |
Use scripts to list recently files
- (Advanced) Write a command or script to recursively find the most recently modified file in a directory. More generally, can you list all files by recency?
1 |
|




